How To Run Facebook Ads To Merch by Amazon Listings
How many of you just landed on this guide and have already tried running paid advertising to your merch listings? Out of all the people that have, I bet the vast majority of you ran paid advertising using Facebook ads and reported back that they were expensive and a waste of time.
I have been there! Being involved in the affiliate marketing community over the last few years before I got involved in Merch by Amazon and print on demand, I burned 10’s of thousands of dollars on Facebook without making all of that money back. I certainly do not claim to be a FB ads expert but all of that ad spend did teach me a few things that we at Merch Informer have been playing around with Merch.
Instead of paying someone (who probably has no idea what they are talking about) for a guide on running paid traffic, learn it for yourself with all the free information available. No one is going to give away all their secrets unless they have something to sell (Have you signed up for our 3 day trial yet?), or they are just trying to make a quick buck.
So with that being said, let’s get into some of the strategies and what I think the major issue is with running FB ads and how you can fix it.
Facebook Ads For Long Term Growth
One of the biggest mistakes that I see in the Facebook groups as well as the POD space is that people run Facebook ads towards a shirt that is nothing more than a trend. They are trying to capitalize on something that may only be a “thing” for the next week or so. This CAN work and lead to a lot of extra dollars in your pocket, but it is also playing with fire.

You know who is also running ads towards trendy tees? Everyone else!
Not only is everyone else in the Facebook game and POD game trying to game the same system for the same trends, but not everyone is going to win that game. There are going to be a lot of losers and when it comes to FB ads, you need to do a lot of testing to get a profitable campaign. If you are afraid of losing 10-20 dollars a day, you should not even be considering running paid traffic at all. Not every campaign will make you money, and you need to be comfortable with that to be successful with the methods we will talk about.
So what should you be focusing on if not trends where there is sure to be massive demand for a while?
Evergreen designs in highly competitive niches!
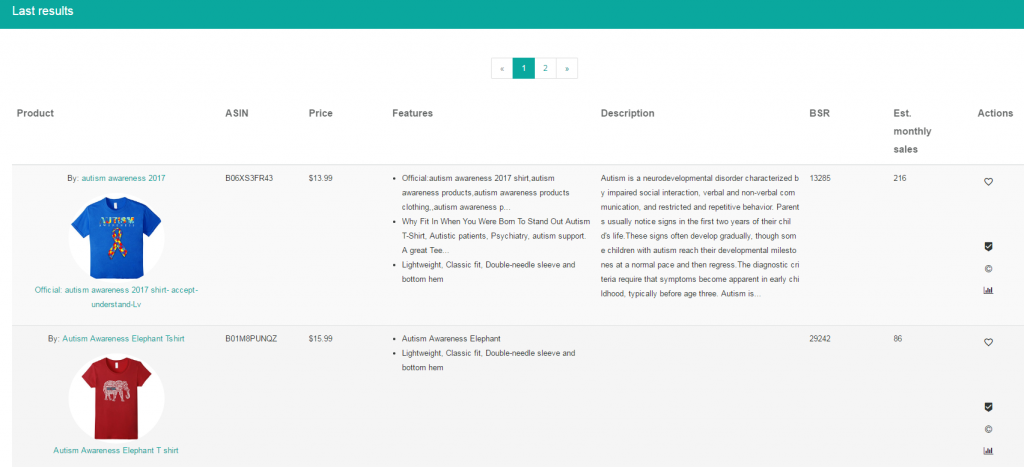
Take the niche above for example. The autism niche has a ton of great shirts but there are a LOT of shirts available in that niche because they sell well, but the people that buy them are very passionate about the cause.
If you were to put a shirt up in this niche, it would be very hard to get organic sales because you would be up against over 6 thousand other results. Sure, you could play around with price and getting your bullet points just right with the correct keywords, but even then, you would be fighting an uphill battle.
In order to get the BSR rank that you need and rank in the search results, you will need sales. If you can get just a few sales, this will boost your BSR and also your search ranking position which will lead to ORGANIC sales. Once you are ranked in niches like these and get a few reviews coming in, they will continue making profit for you years down the line.
If you take anything from this entire article, remember this:
Sales from external traffic = higher organic rankings
This means your paid traffic campaigns with Facebook ads do NOT need to turn a profit right away. You only need to aim for break even or even a slight loss. If you take a $100 loss this week but get enough sales from your $100 loss that your product is now ranked and brings in daily organic sales, you come out WAY ahead.
Your $100 campaign loss might turn into $5,000 net profit for the entire year. Worth it right?
You might not even come out in the red right away. The end goal is to ALWAYS break even. Optimize until you break even.
Non Seasonal Niches
To get started with the Facebook ads below, you need to have a few things picked out.
First, you need to find some keywords/niches that have a good amount of monthly sales. I would say anywhere between 50-100 (or higher), is where you should be aiming. Use the Merch informer Product search to dig up best sellers like the the screenshot above.
You also should be using the Keyword Tool to make sure that the niche is not seasonal. You do not want to be running ad spend for a niche that will only bring you money back for a short period of time and then go dormant for the rest of the year. This is a waste of this FB ads technique.
Running Facebook Ads
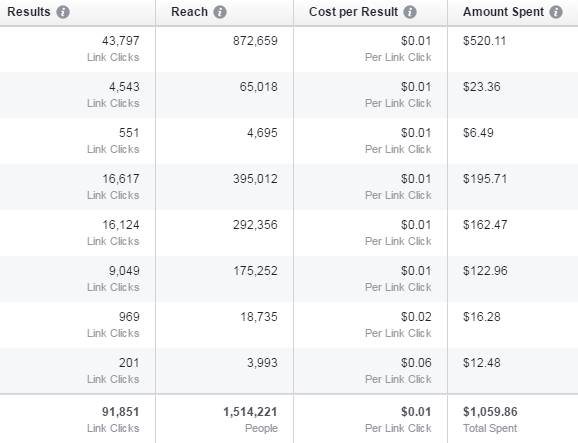
First, let me show you an image of what I was able to achieve by playing around with this method:
Now that you know what is possible, let me go into HOW to get these cheap clicks, and how you can use them to actually get sales.
Stick with me on this one, lets do it.
Thought Process
If you have never run ads before, this might be a concept that is not familiar to you. The way they generally work is that there is a pool of people (the audience), and each advertiser bids for that audience kind of like an auction.
Econ 101 is at play here meaning good old supply and demand are going to influence how much people are paying for clicks depending on what audience you are going after.
In this scenario, people have a cost, and some people are more expensive to reach than others.
Why might one demographic be more expensive than another? Value! You hear it time and time again in marketing circles, but certain people just provide more value to your business than others. This same concept can be used when thinking about Facebook ads.
Testing
Using what I just mentioned about the value of the user, the thought was that if I could find people that were plenty in “supply” but not many people were advertising to (low demand), I could get a ton of engagement.
The content that I decided I was going to test this out on was just a single Amazon T-shirt post that I had put up one of my Facebook pages. Keep in mind there are a few ways to get cheap clicks, and this is one of them.
Picking Your Low Demand Audience
In order to get the cheapest clicks possible, I needed to advertise to people that no one else wanted to run ads to. This is what I came up with:
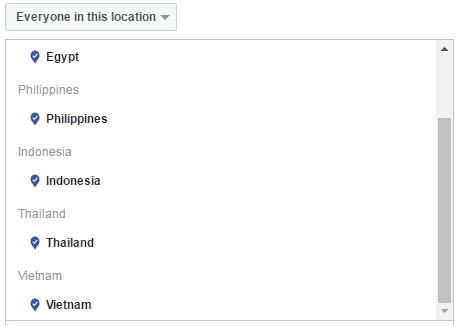
These countries seemed to work extremely well for this experiment.
Pro tip: running ads to Spanish speaking countries also seems to work great.
Now you might be sitting here saying to yourself, okay, so how does that help me? We will get there, I promise!
The reason I think these countries are so incredibly cheap to advertise to is that not only do they have a low purchase intent, but they generally have a LOT LESS income that they can just blow on random online purchases. The English speaking population is also much less (try running ads to non English speakers if you want the cheapest clicks you have ever seen).
After you pick your audience, you need to throw a few interests in there. Since the main population of those countries is going to be massive, we can niche them down just a bit based on interests which is actually going to come in handy with the second part of how this technique works.
For this particular ad, I set up the interests like this:
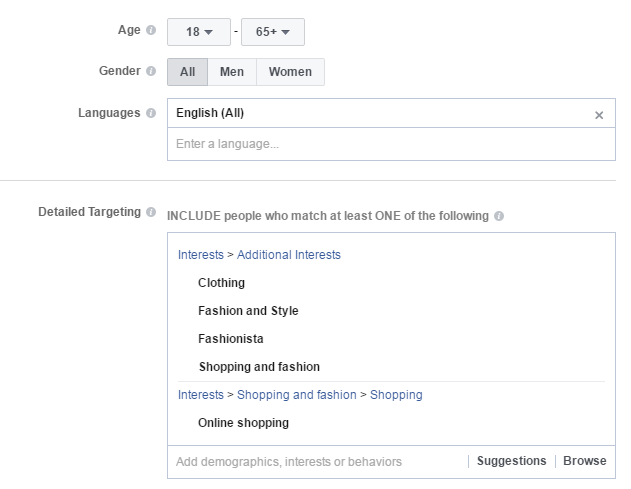
One note here. You can pick a gender or not. This should be tested, but from my experience, if you pick men as the gender for this step, it makes the ad itself perform a bit better.
Creating Your Ad
So why a male audience? Because you are going to take the image of your shirt, and use a mockup of an attractive woman to get your conversion up. Conversion plays a large part in how cheap your clicks are.

When you make the post itself, you can either insert an Amazon link into the actual heading there (remember we are doing a page post here), or you could use a service like https://www.sell.io/.
If you are wondering where we got those sweet looking mock ups: https://placeit.net. The smaller images are free with an account, the larger ones you will need to pay for. If larger ones are what you want, get 15% off by clicking this link here.
Boost Your Post
Now that I had an audience picked out of countries that no one was advertising to, a few interests to make the ad work a little bit better, and the post published to my page with a nice mockup, it was time to boost it.
Quickly it became obvious that it was working. The audience was mostly male and would you look at that, CHEAP!
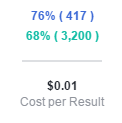
You can play around with your audience, but you will soon see that you can get 1 cent to even cheaper clicks. Some of my campaigns are at half a cent a click.
Not only that, but some of the people in your audience are going to be liking your Facebook page and the boost even sometimes causes organic reach, not a bad deal.
But why?! Why would you ever care about hundreds or thousands of likes from countries that are not going to order from Amazon.com in the first place? This will not drive sales or leads and gives you zero value right?
Wrong!
Social Proofing The Real Buyers
If you ever took a psychology class in school or read a psych book, you may have heard the concept of social proof. We are constantly reading testimonials and word of mouth advice about specific products from real customers if that service or product is worth it. This is one of the reasons why reviews on Amazon work so well, social proof!
It is hard for people to say no if everyone else things X is the best thing ever!
By running the ad to the cheap audience, you can gather thousands of likes on your content with some awesome comments and that is all we need it for, social proof.
We can then run a campaign to a targeted audience that is going provide value to our business at a CHEAPER rate (because higher engagement), and a higher purchase rate (because of social proof)
Creating Your Ad
This part is easy because you are going to use the same post with all the comments but just change out the different locations you are advertising to. Change it to a United States audience and keep the interests the same. You also will want to narrow down the interest audience with the niche of the actual shirt.
Split Test?
You may wish to split test with the same post promoted to a United States audience and the post with all the likes promotes to the same audience.
Let me save you the time and money though!
The post that was promoted to the new audience that ALREADY had all those likes, cost 73% less than the post with zero likes. Crazy right?
Using this technique, I was able to get engagement to right under $0.29 cost per engagement.
Using This Technique
Using the technique I outlined above, you should be able to get your cost per click or cost per engagement (depending on what type of ads you are running), down to around what I am getting.
If you run your shirts at $19.99 on Amazon, that gives you $7.68 margin to work with (very soon to be 50 cents less).
That means at around 29 cents per engagement or click, you need to make a sale in 24 clicks to break even which is the goal. Remember though, you do NOT need to break even for it to be worth it. You might take a small loss just to get a few sales which will kick you up in the organic results.
In order to see the best results using this technique, you need to run at least around $20 to see if it is working for that particular shirt. A lot of people will run $5, see no sales and give up. This is not a good technique for Facebook ads at all, so do not do it. If you do not have $20 to spend on ads, this technique is not for you.
Bonus Technique For Cheap Clicks
Something I have been playing around for both Merch and another business of mine, has been video ads.
The same exact concept applies that we went over above. Use lesser valuable countries to give your video some social proof and then use that same video for the valuable audience.
Since not as many people are running video ads, these are even CHEAPER. Not only that, but from the small amount of testing we have done with video ads, they seem to get more engagement and higher purchases. Pretty good stuff if you are willing to test.
You do not need to make a video yourself, you could always get one of videos with someone wearing your design from placeit.net where we got the mockup we used in the example above.
Thinking Outside The Box
For those of you doing Merch in other countries via drop shipping, or any other method, you can use this to make insane money. Those audiences that we keep changing out for USA based audiences? Ya, those people actually do buy stuff if you hit them with what they want. If you can find something you can sell them that will ship to their country and get 1 cent clicks like we were able to get, you can make so much more money than selling to a USA based audience. It is all about testing! There is so much you can do with the cheap clicks you can get from Facebook traffic but the social proof which leads to lower cost in the USA audience technique that I described above has been working consistently for us.
Remember when I gave the pro tip of Spanish speaking countries? A lot of the ad spend in the image above from my Facebook ads account was direct to that audience selling directly.
Wrapping It Up
Remember, if your campaign is not directly profitable right away, that is just fine! you need to take into account the long term sales that you will get from the organic traffic because of the few sales you made with the campaign.
If you spend $300 on a campaign that brings you 10-15 sales, you might be thinking to yourself that you failed and lost money. If you got those sales in just a few days though, your Amazon listing is going to skyrocket ahead of the competition and organic sales are going to start coming in day in and day out. If you make sure your design is top notch, that ad spend loss (or break even!), could turn into 50 sales a month for you all year long. A small adspend can easily turn into $1000’s in recurring monthly revenue with this method if you take the time to learn and test it! Good luck!



What about for people who are not approved by merch by Amazon. Just use shopify?
Shopify or Teespring work great.
Great article, Neil! If I set a specific ad spend budget for a particular shirt, or niche of shirts, do you think it’s better to spend more per day and have the ad run for a shorter period or spend less per day and have the ad run longer? $20/day for 5 days or $5/day for 20 days?
I think spending the same amount of money over a single day is going to get you the best results overall since if you are making sales, then the BSR will spike faster, thus giving you a better organic position.
But with Merch by Amazon, Amazon doesn’t ship outside the USA do they? Because it is a Amazon “Prime” item. Was this article specifically for those selling shirts outside of the Merch by Amazon program and just on Amazon in general? Great article!
The entire point is that you can get those cheap likes for social proof and then switch the add to sell to people in the USA and have higher engagement on those ads because of the cheap clicks. You can also figure out ways to sell to the cheaper audience directly and turn a lot higher ROI.
My gut feeling is that Merch products in general are more likely to be bought by men but I have yet to see any research supporting that but anecdotes about sales occurring late at night/early in the morning would support that (though that is based on another assumption). I know Amazon isn’t sharing the data it is collecting have you run across data anywhere else? My assumption would be that more men are spontaneously buying joke shirts whereas women would be more likely to be searching for gifts. But the problem with assumptions is that unless you see the data (or test rigorously) I could be completely full of shit even if 99% of the people around me also believe the same things.
Funny enough, a lot of the reviews we have seen on our own shirts have been from Women buying gifts for other people. You might be on to something.
Hi Neil,
Great post as usual! A couple of questions on the implementation details:
1) Do you set an automatic or manual bidding for the ads in the non-US and the US?
2) Each post engagement requires a facebook page. What do you usually put there?
3) When you say that 20$is necessary for ads, do you mean 20$ per campaign for non-US and the US markets altogether?
4) Do you have an advice on what text to put in the headline, ad copy and description of ads?
5) Do you create separate campaigns for each design or it doesn’t matter?
I usually set automatic bidding on Facebook ads for both audiences and we use just a dummy facebook page about shirts. From testing, you do not need to run much with the non US market. Just a few dollars should do if the clicks are cheap enough. For the headline and ad copy, just keep it simple. If they are simple and the design sticks out, you will do well. I would suggest creating separate campaigns for each design that you promote.
As always, fantastic information here. Just followed your instructions, and feel a lot more confident moving forward with this blueprint in mind. Thanks!
Great article Neil!
Question, I’m not in Merch by Amazon yet, I still waiting to get in. This process you explain here can be done using Teespring integration since I have a couple of designs showing up in amazon through Teespring I can use that amazon link for the FB Ad? I guess yes but want to confirm with you and know your opinion. Thanks!
Of course you can! Amazon loves people driving traffic to them.
Hello Neil,
I see that you are targeting non-US audiences, but when I want to return to US ads. You do edited curent adset or create a new adset from old article?
Thanks!
You would edit the current adset so you have the social proof on that ad.
Neil, have you found a difference between driving the post engagement through the ads and through the “Boost Post” button? My guess is that the latter is a just simplified version of the former in terms of settings and eventually a user see the same ad. Is that a correct assumption?
Actually prefer the boost post button because this will grow a generic t-shirt page as well, and you can easily just switch your audience.
Hi Neil,
I wanted to try video ads but was very surprised by the high price on the placeit.net for them: 29$ per download or 199$ per month. Do they really work so much better than 30$ spent on a single image ad?
Probably, you have the unlimited subscription since you have thousands of shirts and run many campaigns and it justifies the cost.
A much cheaper option would be to just purchase your shirt and have someone you know wear it and create your own short video. The video ads have such a super low CPC that in the end, it really does seem to be worth it.
What’s your engagement threshold (number of likes and comments) to switch from the non-US audience to the US?
I usually just run a few dollars worth of the cheap traffic before I switch it over. This is going to be different for everyone though, so test it for your niche.
Is there a reason why you didn’t include India in the list of the non-US countries? English is one of their main languages, there is a lot of people and it has a low cost of living. The ads should be cheap there too.
Something to test for sure! No particular reason at all it was left off, just did not cross my mind when creating the add. Good add!
Hey Neil, awesome post, thanks a lot! Working on your idea and I already have 40 likes after spending about 50 cents advertising in Latin American countries. Do you suggest waiting for my campaign to end (24hrs) before I retarget to US customers, or should I do it after a certain amount of Post engagement? Thanks again, I love Merch Informer!
This is something you will need to test. There is no definitive answer here. Awesome to hear you are getting cheap engagements!
Excellent write up, I’m going to be trying this later this week with a shirt that has about 20 sales per month organically.
How many likes is considered “good” for every $1 spent? I know this will vary based on niche but what’s the average?
There really isnt an exact statistic for that and it depends how much you are paying for click
Neil – Are you saying that simply having a lot of traffic to an Amazon page coming from outside Amazon (and converting a bit) – is going to make that page appear high in Organic search?
That is correct
Would it not be cheaper just to buy every one of your own Merch shirts?
Not if you get your campaigns to work correctly!
Genius. Just… ugh. Good thinking my man haha. Anyways. So didn’t realize my blunder till after I set up a campaign and let it rip.
Do you make a post, then boost? Or run an ad, via ad manager?
Boost makes sense, as it keeps all the social proof on one post per say, that can later, be re-boosted.
Or…
do you… as I plan to now, due to my what I think is a F UP.
A. Gain high traffic benefit overall from the low quality clicks by sheer organic boost for the whole campaign legnth.
B. Do Option A, but then switch targeting of ad to USA say, 1-2-3 days into it, after the social proof has settled in.
I’m overall testing, so i’m letting it run regardless. And set up a mirror ad, with a call to action, targeted properly towards the niche. To see which pulls better results. Low Quality into Targeted ADs mid ad schedule or direct targeting the whole time.
You will have to test which is sounds like you are doing. I personally like boosting ads on a general t-shirt page so that the social proof stays and the page grows even larger.
Just wondering if you tried using a link and replacing the default Amazon image with one of the mock-ups? I tried and it seems to crop the mock-up, and thus the shirt. You also can’t really change the link description, which is a shame.
The benefit, however, is that all those people who would have clicked on the image will now click the link, thus giving you more traffic. I don’t know if that’ll get you more direct sales though. Guess I’ll just have to try it…
Also, how many cheap likes would you say are necessary to effectively social proof your shirts for US buyers? I spent $1.50 and got around 500 likes, which already seems like a lot.
I would say 500 likes is more than enough! You will need to play around with how you put the links and images but personally, I like to drive traffic to a landing page. The secret there, is that even if the cheap traffic does not convert on the landing page, I can control exactly how the image on Facebook and description look like.
First off, thank you for this. It had some extremely useful information and explanation in it! But I have a question. I’m a total noob with Facebook ads; do I use an actual ad set that is part of a campaign? Or is there some other way to do it? I just made my first ad through the ad manager and I’m running it for the overseas audience but I’m not too sure how to use that traffic/social proof and transfer it over to a different audience. Maybe I’m just not seeing the option. Is there a quick way for you to describe what type of post to use, and which options in particular I need to choose in order to transfer all of the social proof to the advertisements that I run for the actual buying audience (US)? Thank you in advance.
You can just run a boosted post from a Facebook page and then when you are ready to change the audience, simply boost the post to US based audience.
Thank you! That makes so much more sense!
I’m not clear on the direction of traffic. Are you linking to the Amazon listing, a page on your Shopify store or a fanpage from the ad? You mentioned a landing page, but what does the landing page do? DIrect to Amazon or collect emails or something else?
You can link directly to amazon or use a landing page like sell.io or even your store to collect emails up to you really.
Did you only create a page for that niche for autism? Or was it a FB page for numerous other niches?
I mainly use a general t-shirt page.
Hey,
Thanks for a great post. A quick question: can you use Amazon affiliate link in your Facebook ads?
I wouldn’t.
Hi Neil,
Thanks for writing the article, found it very useful 🙂
A question: when creating the FB ad for a product on Amazon, for “Website URL” we’d input our website’s landing page and at the “Text” section we include the link to the product page at Amazon? Is this right?
If instead, I placed the link to the product page at Amazon at “Website URL”, then the FB pixel won’t be tracking anything when there’s a conversion? Because my FB pixel is set on my client’s website, not at Amazon?
I am wondering which link should I set on which section when creating the FB ad. Thanks and looking to forward to hearing your advise 🙂
You want to link to the page of a website that you own. If you do not, you will not be able to track anything because there is no way to put the FB pixel on an Amazon page (since you do not control Amazon pages). Put your landing page in, and for text, put in some sales copy for the shirt, not a link to Amazon. You have the link to Amazon on your landing page.
Thanks for your prompt reply Neil, got it. Appreciate you taking the time to answer 🙂
You can generate tracking links with retargeting pixels pointing to your Amazon product page. Then, you use those links in your campaigns to grow your custom audience and retarget them with more customized campaigns later.
Are you using Pay Per Engagement as your ad type when you switch over to the buyer traffic? Or, are you doing website conversions, add to cart, etc?
Will generally just do pay per click to get them over to my landing page. This is something you will need to test though.
Neil, question, when you say ‘boosting ads on a general t-shirt page’, what exactly do you mean by that? Could you explain further what a general t-shirt page is, in theory, and the best way to set this up?
Would this page be like a simple “I love t-shirts” page, with a collection of pictures of t-shirts we love, which many would be in actuality the shirts we are promoting / boosting? I’m trying to grasp the process in steps. We would be gathering social proof and followers to this t-shirt page as well as converting socially proofed posts into US-based ads, eventually?
Correct. It would just be a Facebook page centered around t-shirts (not a particular niche) but just a collection of shirts. The page itself does not need social proof, only the post you are boosting, which is why we switch the audience.
thanks!
This is great post Neil. I’ve been loosing money on Facebook Ads trying different tactics..
But this tactic is new for me… getting social proof cheaply and then using it to get real customers.. Cool…
I will definitely try it and will share my results here.
Thanks
This is an awesome post and a real eye opener for me! I also recently watched your presentation from the Proven Merch event, and I enjoyed it!
I’m hoping that you can help me understand something.
I don’t think that FB will let me change the link in the ad after it goes live, so I’m trying to figure out the logistics of the Amazon link placement.
I’m concerned that if I put the Amazon link in the social proof ad, it will hurt the listing because multiple visits to a listing with no sales is not a good thing for the Amazon algorithm.
I saw one of your responses above about having a landing page with the Amazon link on it. I’m assuming the thing to do is to leave the link out for the social proof countries and then put it back in (or set up a redirect to the Amazon page) once I start targeting US based audiences.
With all of that said, will that hurt the listing on Amazon if all of this traffic is coming from the same landing page/redirect? (It might not look natural to Amazon)
Also, if I’m not on the right path with the link placement, what do you suggest?
You nailed it on the head with the landing page. What you would do ideally would be to run the add itself to a landing page. You can then include if you want a link on that page or else add it later. Even though the traffic would be coming from a landing page, that is not going to be bad in Amazon’s eyes. This is actually how a ton of people launch private label products. Amazon loves outside traffic as long as its the right traffic!
Ah, I had a feeling this was the way to do it. I have a Shopify site with another POD company. I was thinking of running ads to that page but it takes forever to set up one product with their horrible app. But I agree, the bounce rate on those tshirt landing pages would be horrible and hurt us in the eyes of Amazon. Thanks for the question and answer! 🙂
Hi Neil
Apologies for the reply to this dated comment thread – but my reading of this is that this is a very important consideration in the success of this FB ads strategy.
Given that this strategy is based on the idea that external traffic leads to higher organic rankings on amazon, and aims to leverage:
cheap clicks (low / no quality non-US traffic) > social proof > cheap clicks (quality US traffic) > boosted BSR and ranking;
is it the case then that the landing page intermediate is absolutely necessary?
Otherwise, if our low cost low quality traffic is clicking through with no purchases this could potentially hurt the listings ranking more than the eventual boost from quality traffic?
Interested to hear your thoughts!
I have not actually tested this too extensively in regards to ranking, but I think an in between landing page would be a HUGE help because this would not only allow you to properly track the traffic once it is off Facebook, but it would also let you retarget this audience at a later date with the retargeting pixel.
Did placeit stop giving free ones? I bought one for $8 because I couldn’t find a way to get a low-res for free.
I believe they did!
You can either take a screenshot of what you see on your screen or drag and drop the image to your desktop. Nevertheless, this image will have the Placeit watermark. 🙁
Hi Neil, in your example are you using an image post, i.e. a big jpeg with a link alongside it? Or a link post, where it creates that auto-preview, i.e. as if you were posting a news article?
Great article!!! I just started Merch and have tiered up to 25 in one week. As of today, March 2, 2018, can we still run ads directly to Amazon Merch tshirt links? Not one person will answer me in any of my paid and free groups, so I’d really appreciate your help and will check out your membership tool, too.
Yes you can!
Hi there, great post. I’m now running ad using the tips from your article. The Ads Manager show $0.002 Cost per Result. Gathered about 125 on Facebook and 2000 likes on Instagram and spent ~$3.15 now. I am impressed. Ready for switching to the target audience.
Anyway i think it’s nice strategy for promoting and long term growing for my T-shirt merch business and digital graphics (sell designs on different stores as well). I’m new on Merch, have only 10 tier and extremely need sales to ̶t̶a̶k̶e̶ ̶o̶v̶e̶r̶ ̶t̶h̶e̶ ̶w̶o̶r̶l̶d̶ tier up 🙂
Thanks again
Eugen.
Thanks for this article. Trying it how. Question: When selecting the Objective, do you choose Website Visits or Engagement? This can’t be changed unless deleting the promotion so I’d like to get it right for the best outcome. 🙂 Thanks in advance!
Visits!
Hi Neil,
I am sorry for dated reply.
It’s a very nice and useful article thank you a lot.
I am new user on Merch By Amazon with Tier 10 and I have 10 designs without any sale until now from one month.
I will try to do your steps for FB ADS ads which I already test before but with no hope.
I have my website and I will create a page for selling like a land page.
But how you suggest Amazon links should be inside the landing page; should it be like just images with links or products and cart.
Thanks in advance for your advise.
Hello,
Thank you for your resources. I have been a lurker so far, but I’m so close to purchasing your product.
I was wondering.
Would you be so kind and share a caption of one of your listings that work?
Kind regards,
Alan Jereb
A caption from a selling product on Merch?
Facebook AD caption. Sorry for being unclear.
Alan Jereb
Hi what kind of campaign goal should i set? Traffic, engagement etc?
You will want to play around with it and see what works best.
Hi, how do I upload a photo showcasing the while picture of the girl, rather than the dimention something like 600×1200 only allowing me to either show her face, or her shirt.
*whole and dimesion
Great tip, thanks Neil. Having a merch by amazon account and a son with autism, too bad this is a very crowded niche, since it’s a topic dear to my heart 🙂 Anyway, who never tries will always fail …so let’s do it
How does thia garbage get to the top via SEO on google?? Win by losing? Make money by losing money strategy? FFS, you should be ashamed of this garbage.
Ashamed for showing a technique that actually works?
HI Neil, you do really great article and this one i really awesome, but would you please do an article takes us step by step on how to create the FB Ad it self, do we need to create FB business manager account or not. i followed your other article in setting up my Instagram and would appreciate taking us as well step by step in setting the Facebook ads, also if possible it would be great guiding us on how to market our Merch through amazon it self if.
in 2020 what changes for this strategy?